
My data generally comes in pairs of two rows, and when the action is successful, the key in column 2 of the first row will match the key in column 1 of the second row.
I am trying to find a way to look at the row ahead to compare them, and if they match add some new identifier for these two rows into a new third column, but I am having a hard time figuring out a good way to look ahead.
Any ideas? I really appreciate any assistance.
I am trying to find a way to look at the row ahead to compare them, and if they match add some new identifier for these two rows into a new third column, but I am having a hard time figuring out a good way to look ahead.
Any ideas? I really appreciate any assistance.
-
Hi welshed2,
There are 2 answers depending on your CloverETL Edition:
For paid/trial version:
1. Split your source data into 2 record streams using either http://doc.cloveretl.com/documentation/ ... ition.html or http://doc.cloveretl.com/documentation/ ... ilter.html . One stream for first rows, the other for second rows. I expect you can distinguish first and second line.
2. Join this 2 streams using http://doc.cloveretl.com/documentation/ ... ction.html . It allows you to handle 3 possible states: there are both rows joined via key, there is just first row, there is just second row. When both your records are presented, you can build new record from them.
For OSS/Community version:
1. In viewtopic.php?f=4&t=6849&p=11048#p11054 I shown you usage of variable persisting during whole transformation. Instead of simple bool you can use there metadata defined type and store whole input record. See "record" here http://doc.cloveretl.com/documentation/ ... -ctl2.html So you can't look ahead, but you can see previous record. That means you would compose result record when you hit second row. You can see even more items in history if you incorporate "list" type.
2. Reformat can have 2 outputs and those may be driven by http://doc.cloveretl.com/documentation/ ... alues.html . So for first row you can return SKIP, for second set data on both ports and return ALL.
3. Use http://doc.cloveretl.com/documentation/ ... ather.html or http://doc.cloveretl.com/documentation/ ... merge.html to join data from Reformat's 2 output ports. Just keep in mind this may scatter your data so you will probably need to incorporate sorting (you can add extra column using http://doc.cloveretl.com/documentation/ ... lling.html having index of source line).
I hope this helps. -
Thanks so much for the reply, I appreciate the response.
I have a paid version, and unfortunately, there is no real way to distinguish row 1 from row 2, and not all entries have a row 2, so I cannot just filter every other row.
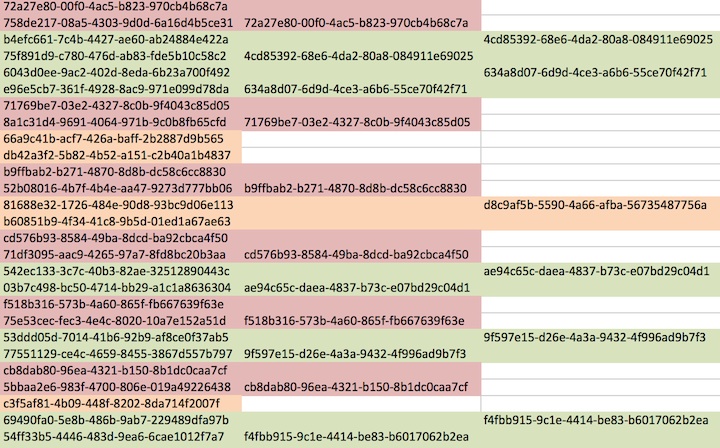
I have attached a sample of my data (coloring was done by me for clarity). Green and pink rows have matching data in a subsequent row, while orange rows are alone without a matching row. The individual orange rows throw off the alternating pattern.
If I can do it in my head, the logic exists to automate it, I just can't figure out how to put it into CloverETL! :P
screenshot.jpg -
Hello,
I can see that in case of pink rows, field1 of row1 and field2 of row2 contain the same value. In case of green rows, field3 of row1 and field2 of row2 contain the same value. Is this observation correct?
If so, you could create two global variables and store field1 and field3 of every row there. If one of them matches to field2 of the following row, you could save information about the first row of the pair in a lookup table or a temp file. You will get a list of "the first rows" this way and you can add an identifier to them and their followers ("the second rows") in the second cycle.
Is this description understandable? Let me know if you have any questions.
Regards, -
Hi,
I have prepared a short example for you that might help you understand how transformation like this can be handled. Solution would be to partition data based on the matching condition. In other words, if a field in the second column has the same value as the first field of a preceding row, send the record to a particular output port. The same is done with the other matching condition (2nd field of current row is the same as the third field of preceding row). This way we get data on three different ports. One contains first rows of matched records and all other unmatched records. The other two records do contain records that have matching record. Of course, you can assign appropriate identifiers to each row (one identifier per pair) to join and work with data. For more details, please review attached project.
I have also noticed you have created another thread that relates to this one, so I’d like to ask you whether this example helps you with the other one.
Thanks.



{kind=link}
Please sign in to leave a comment.
Comments 6