
Hello -
I want to write out multiple files that group employees together. Each file should be about 20K in size. I am using universal data writer and set the partition key as ' employee id '. However that created one file per employee and I have about 170 employees in the incoming file and each employee has a several records. How can I ask clover to write out multiple files but group employees into 1 file until the file reaches 20M in size or 20K-ish in records number, then start to write out a new file with another group of employees?
Right now, if I dont use partition key, Clover just write out 20K per file, but some employees get put into different file. If I set the partition key, then each employee gets one file.
Is there a mid-way approach?
Perri
I want to write out multiple files that group employees together. Each file should be about 20K in size. I am using universal data writer and set the partition key as ' employee id '. However that created one file per employee and I have about 170 employees in the incoming file and each employee has a several records. How can I ask clover to write out multiple files but group employees into 1 file until the file reaches 20M in size or 20K-ish in records number, then start to write out a new file with another group of employees?
Right now, if I dont use partition key, Clover just write out 20K per file, but some employees get put into different file. If I set the partition key, then each employee gets one file.
Is there a mid-way approach?
Perri
-
Hi Perri,
In writer components, there are "Records per file" and "Bytes per file" attributes that do exactly what you are looking for. In case you use any of these attributes, you must add dollar signs ($) placeholders (file numbering) into URL.
For more information about these attributes, please refer to our documentation: http://doc.cloveretl.com/documentation/ ... riter.html
Hope this helps. -
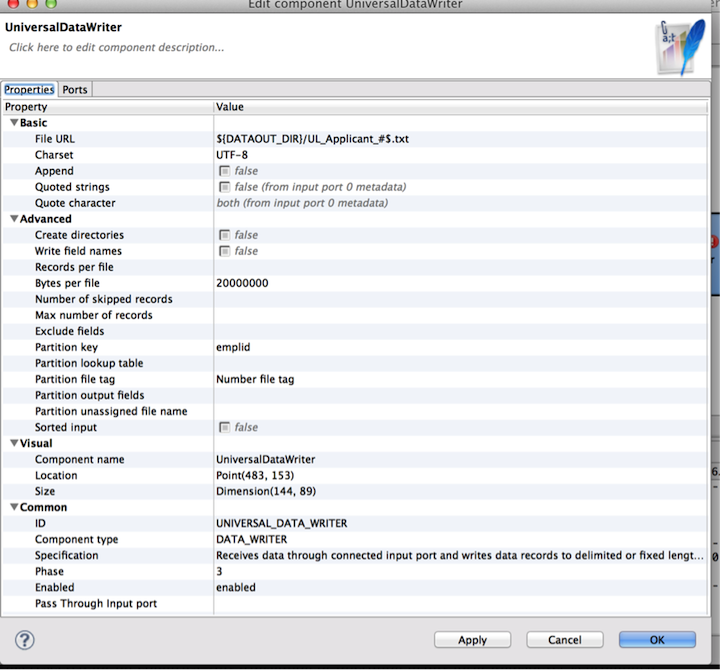
I tried that, it still outputs 1 file per employee. I attached the configuration of my writer component.
Let me know what I didnt configure correctly.
Thanks,
Perri -
Hi, I attached the graph. I changed the byes to 5000. Right now, it is still writing out 74 files because there are 74 emplids. For some reason, I cannot attach the test data, it says that "The extension xlsx is not allowed".
I am using Clover Designer Community version.
Thanks,
P -
Hi Perry,
Please take a look at the attach graph (whole project is in the zip archive). Could you please try to run the graph and check if the input data in the zip archive are transferred into correctly partitioned output files? You should get three files partitioned per key and per number of records. In the graph you have attached, you were missing dollar sign, which is necessary when you use "Records per file" or "Bytes per file" attributes.
Let me know if you have any questions. -
Hi, I ran your graph and it did output three files. However, what I wanted is that employees with the same emplid should be in the same file. In your example emplid - 123186741 is getting outputed into two files, since you set the records per file being 2.
Is there a way I can get the output based on 'byes per record', but don't parse same emplid into two different file?
In sample file you sent, the output should be either both employees John and Martin be in the same file, or John will be in one file and Martin will be in one file (if byes per records is set). My real data set will have over 500K rows of data with 170K emplid. Right now, if it is writing 170K output files because it is putting each emplid into 1 file.
Hope I explained my issue, do let me know if you have any questions.
P -
Hi Perry,
Okay, I think I got what you are saying. In order to do this, you will have to introduce some auxiliary (artificial) key that will help you partition data into files. For this purpose I have calculated byte length of all records with the same emplid. Then I simply assign the auxiliary id to each row based on previously calculated byte length (for more information take please refer to Denormalizer and ExtMergeJoin transformations in the graph).
The project is again attached. Hope this helps.

{kind=link}
Please sign in to leave a comment.
Comments 7